Shortly before finishing
This commit is contained in:
parent
6c1d6762b5
commit
8ec5eb69ab
15 changed files with 511 additions and 15 deletions
6
.gitignore
vendored
6
.gitignore
vendored
|
|
@ -4,4 +4,8 @@
|
|||
|
||||
# Binaries for installation
|
||||
*.deb
|
||||
*.whl
|
||||
*.whl
|
||||
|
||||
# Test data
|
||||
data/pgvector.sql
|
||||
backend.Dockerfile
|
||||
|
|
|
|||
BIN
data/dataset.jsonl
(Stored with Git LFS)
BIN
data/dataset.jsonl
(Stored with Git LFS)
Binary file not shown.
BIN
data/init.sql
(Stored with Git LFS)
Normal file
BIN
data/init.sql
(Stored with Git LFS)
Normal file
Binary file not shown.
12
docker-compose.yml
Normal file
12
docker-compose.yml
Normal file
|
|
@ -0,0 +1,12 @@
|
|||
name: xkcd-finder
|
||||
services:
|
||||
pgvector:
|
||||
ports:
|
||||
- 5432:5432
|
||||
environment:
|
||||
- POSTGRES_USER=postgres
|
||||
- POSTGRES_PASSWORD=postgres
|
||||
- POSTGRES_DB=postgres
|
||||
image: ankane/pgvector
|
||||
volumes:
|
||||
- ./data/init.sql:/docker-entrypoint-initdb.d/init.sql
|
||||
{kind=link}
Binary file not shown.
|
Before 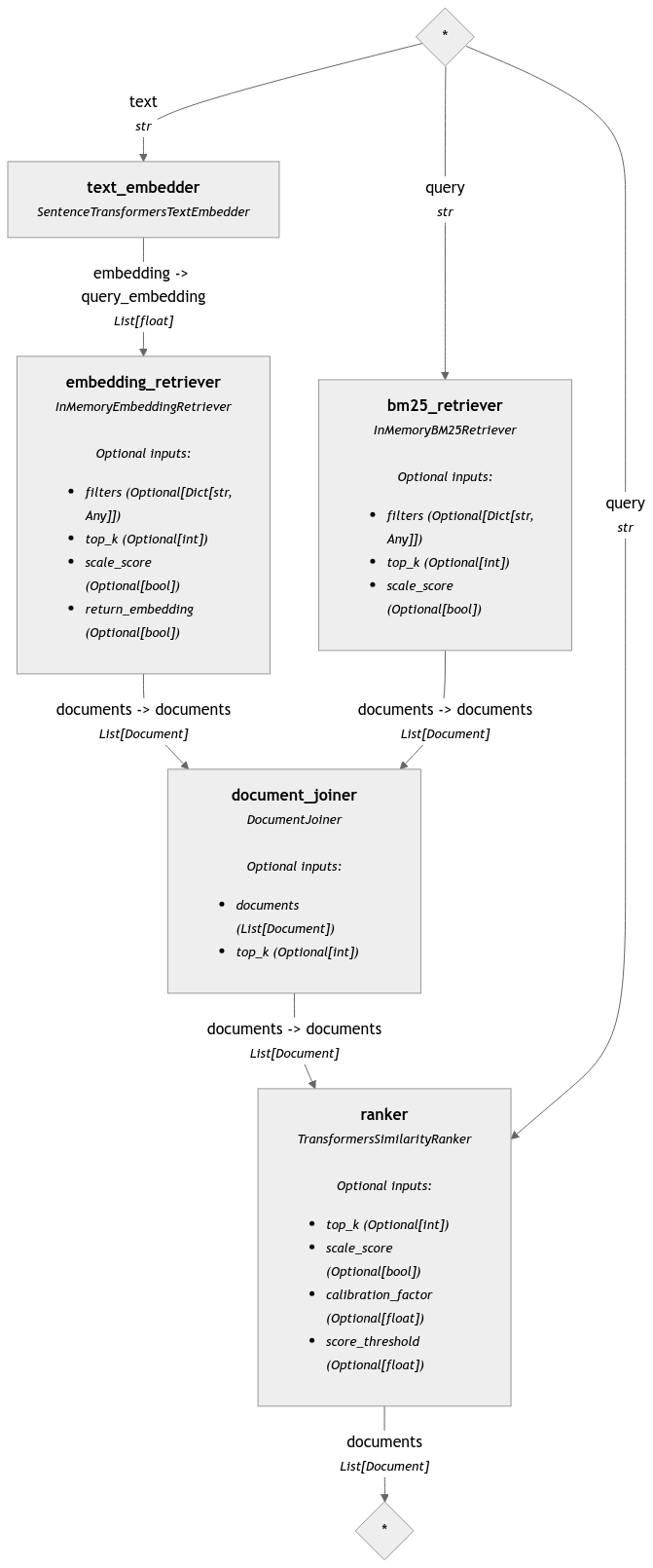
(image error) Size: 128 KiB After 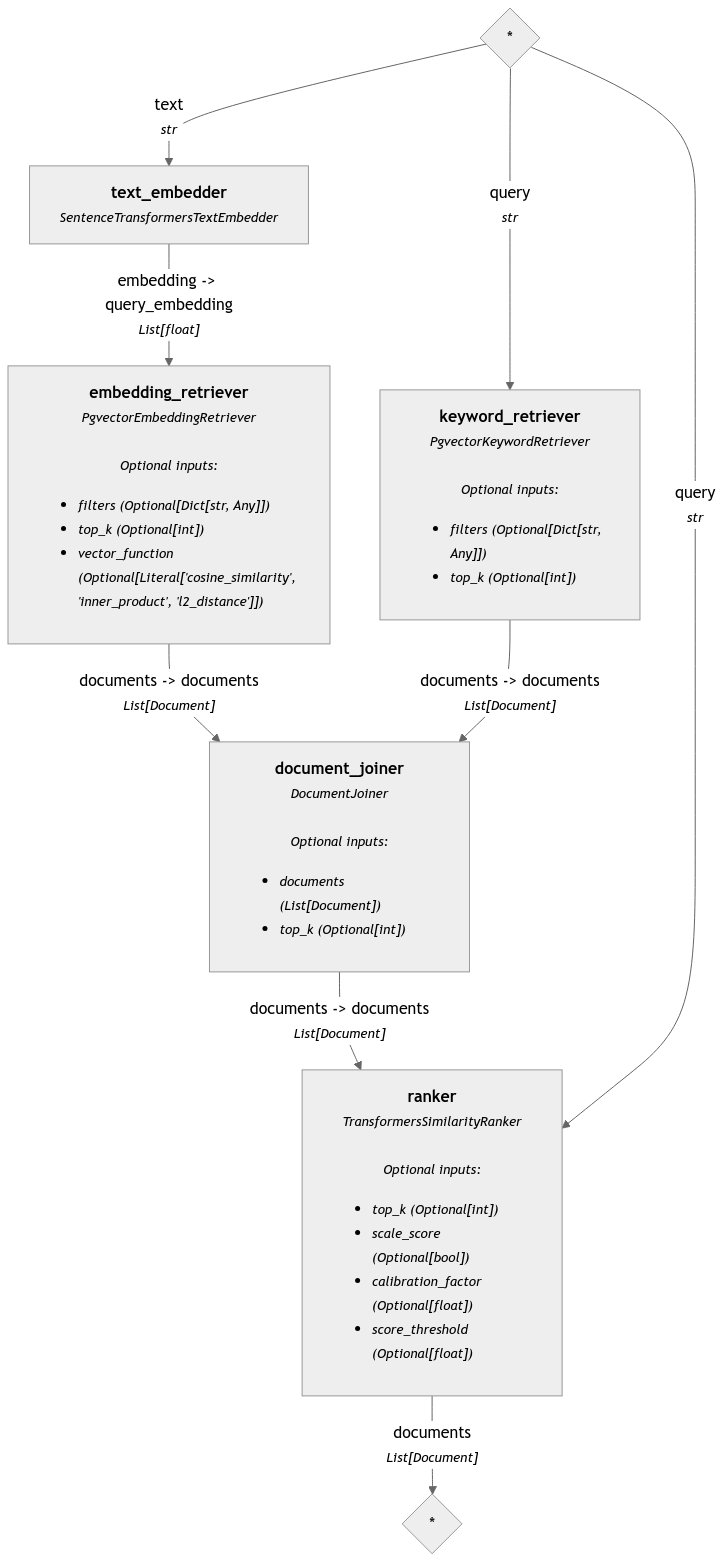
(image error) Size: 126 KiB
|
24
nlp.ipynb
24
nlp.ipynb
|
|
@ -258,7 +258,7 @@
|
|||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "705b147162734470908bbf2ab6d45db3",
|
||||
"model_id": "10c0a04365264393851ab80b8bd3d3ed",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
|
|
@ -316,7 +316,7 @@
|
|||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"<haystack.core.pipeline.pipeline.Pipeline object at 0x7ef6cfa25900>\n",
|
||||
"<haystack.core.pipeline.pipeline.Pipeline object at 0x7f5dd4730e80>\n",
|
||||
"🚅 Components\n",
|
||||
" - text_embedder: SentenceTransformersTextEmbedder\n",
|
||||
" - embedding_retriever: InMemoryEmbeddingRetriever\n",
|
||||
|
|
@ -371,29 +371,29 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Results for 'Give an example for dependency'\n",
|
||||
"Results for 'dependency'\n",
|
||||
"\n",
|
||||
"| ID | Title | Link |\n",
|
||||
"|----------|------------------|---------------------------|\n",
|
||||
"| [ 1579 ] | Tech Loops | https://www.xkcd.com/1579 |\n",
|
||||
"| [ 1906 ] | Making Progress | https://www.xkcd.com/1906 |\n",
|
||||
"| [ 2102 ] | Internet Archive | https://www.xkcd.com/2102 |\n",
|
||||
"| [ 2347 ] | Dependency | https://www.xkcd.com/2347 |\n",
|
||||
"| [ 2166 ] | Stack | https://www.xkcd.com/2166 |\n"
|
||||
"| ID | Title | Link |\n",
|
||||
"|----------|--------------------------|---------------------------|\n",
|
||||
"| [ 1579 ] | Tech Loops | https://www.xkcd.com/1579 |\n",
|
||||
"| [ 2102 ] | Internet Archive | https://www.xkcd.com/2102 |\n",
|
||||
"| [ 1906 ] | Making Progress | https://www.xkcd.com/1906 |\n",
|
||||
"| [ 2347 ] | Dependency | https://www.xkcd.com/2347 |\n",
|
||||
"| [ 1654 ] | Universal Install Script | https://www.xkcd.com/1654 |\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from tabulate import tabulate\n",
|
||||
"\n",
|
||||
"query = \"Give an example for dependency\"\n",
|
||||
"query = \"dependency\"\n",
|
||||
"\n",
|
||||
"result = hybrid_retrieval.run(\n",
|
||||
" data={\n",
|
||||
|
|
|
|||
10
requirements.txt
Normal file
10
requirements.txt
Normal file
|
|
@ -0,0 +1,10 @@
|
|||
haystack-ai~=2.7.0
|
||||
torch~=2.0.0
|
||||
gevent~=24.11.1
|
||||
Flask~=3.1.0
|
||||
pgvector-haystack~=1.2.0
|
||||
tabulate~=0.9.0
|
||||
transformers~=4.46.3
|
||||
accelerate~=1.1.1
|
||||
numpy<2
|
||||
sentence-transformers>=3.0.0
|
||||
1
server-implementation/__init__.py
Normal file
1
server-implementation/__init__.py
Normal file
|
|
@ -0,0 +1 @@
|
|||
|
||||
BIN
server-implementation/__pycache__/backend.cpython-310.pyc
Normal file
BIN
server-implementation/__pycache__/backend.cpython-310.pyc
Normal file
Binary file not shown.
BIN
server-implementation/__pycache__/config_backend.cpython-310.pyc
Normal file
BIN
server-implementation/__pycache__/config_backend.cpython-310.pyc
Normal file
Binary file not shown.
51
server-implementation/app.py
Normal file
51
server-implementation/app.py
Normal file
|
|
@ -0,0 +1,51 @@
|
|||
import pathlib
|
||||
from gevent.pywsgi import WSGIServer
|
||||
from flask import Flask, request, render_template
|
||||
from tabulate import tabulate
|
||||
from wtforms import Form, StringField, SubmitField
|
||||
from wtforms.validators import DataRequired
|
||||
|
||||
from backend import AIBackend
|
||||
|
||||
app = Flask("xkcd_retriever", template_folder=pathlib.Path(__file__).parent / "templates")
|
||||
|
||||
print("Initializing backend")
|
||||
backend = AIBackend()
|
||||
|
||||
# backend.warmup() # Only needed when there is no data in the pgvector database
|
||||
backend._ready = True
|
||||
print("AI backend initialized ...")
|
||||
|
||||
class BasicForm(Form):
|
||||
ids = StringField("ID",validators=[DataRequired()])
|
||||
submit = SubmitField("Submit")
|
||||
|
||||
@app.route("/",methods =['POST','GET'])
|
||||
def main():
|
||||
form = BasicForm()
|
||||
return render_template("index.html", form = form)
|
||||
|
||||
@app.route("/search",methods =['POST','GET'])
|
||||
def results():
|
||||
topic = request.form.get('ids')
|
||||
|
||||
result = backend.query(f"Give an example for {topic}")
|
||||
|
||||
headers = ["ID", "Title", "Link"]
|
||||
print(tabulate(backend.format_result(result), headers=headers, tablefmt="github"))
|
||||
|
||||
res = backend.format_for_api(result)
|
||||
return render_template("results.html", results=res, topic=topic)
|
||||
|
||||
@app.route("/find")
|
||||
def query_backend():
|
||||
topic = request.args.get('topic')
|
||||
result = backend.query(f"Give an example for {topic}")
|
||||
|
||||
headers = ["ID", "Title", "Link"]
|
||||
print(tabulate(backend.format_result(result), headers=headers, tablefmt="github"))
|
||||
|
||||
return backend.format_for_api(result)
|
||||
|
||||
http_server = WSGIServer(("0.0.0.0", 8000), app)
|
||||
http_server.serve_forever()
|
||||
161
server-implementation/backend.py
Normal file
161
server-implementation/backend.py
Normal file
|
|
@ -0,0 +1,161 @@
|
|||
import json
|
||||
import pathlib
|
||||
import config_backend
|
||||
|
||||
if config_backend.needs_torch:
|
||||
import torch
|
||||
|
||||
from haystack import Document
|
||||
from haystack.utils import ComponentDevice
|
||||
from haystack import Pipeline
|
||||
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
|
||||
from haystack.components.preprocessors.document_splitter import DocumentSplitter
|
||||
from haystack.components.writers import DocumentWriter
|
||||
|
||||
from haystack_integrations.document_stores.pgvector import PgvectorDocumentStore
|
||||
from haystack_integrations.components.retrievers.pgvector import PgvectorEmbeddingRetriever, PgvectorKeywordRetriever
|
||||
|
||||
from haystack.components.embedders import SentenceTransformersTextEmbedder
|
||||
from haystack.components.joiners import DocumentJoiner
|
||||
from haystack.components.rankers import TransformersSimilarityRanker
|
||||
|
||||
class AIBackend:
|
||||
model_embeddings = "BAAI/bge-base-en-v1.5"
|
||||
model_ranker = "BAAI/bge-reranker-base"
|
||||
_ready = False
|
||||
|
||||
query_pipeline: Pipeline
|
||||
index_pipeline: Pipeline
|
||||
document_store: PgvectorDocumentStore
|
||||
documents: list[Document] = []
|
||||
|
||||
def __init__(self):
|
||||
if config_backend.needs_torch:
|
||||
get_torch_info()
|
||||
self.gpu = ComponentDevice.from_str("cuda:0")
|
||||
|
||||
dataset = pathlib.Path(__file__).parents[1] / "data" / "dataset.jsonl"
|
||||
if config_backend.load_dataset:
|
||||
self.documents = [ Document(content=d["text"], meta=d["meta"]) for d in load_data(dataset) ]
|
||||
self.document_store = PgvectorDocumentStore(
|
||||
embedding_dimension=768,
|
||||
vector_function="cosine_similarity",
|
||||
recreate_table=False,
|
||||
search_strategy="hnsw",
|
||||
)
|
||||
|
||||
self.index_pipeline = self._create_indexing_pipeline()
|
||||
self.query_pipeline = self._create_query_pipeline()
|
||||
|
||||
def warmup(self):
|
||||
print("Running warmup routine ...")
|
||||
print("Launching indexing pipeline to generate document embeddings")
|
||||
res = self.index_pipeline.run({"document_splitter": {"documents": self.documents}})
|
||||
print(f"Finished running indexing pipeline\nDocument Store: Wrote {res['document_writer']['documents_written']} documents")
|
||||
self._ready = True
|
||||
print("'.query(\"text\")' is now ready to be used")
|
||||
|
||||
def _create_indexing_pipeline(self):
|
||||
print("Creating indexing pipeline ...")
|
||||
document_splitter = DocumentSplitter(split_by="word", split_length=128, split_overlap=4)
|
||||
if config_backend.needs_torch:
|
||||
document_embedder = SentenceTransformersDocumentEmbedder(model=self.model_embeddings, device=self.gpu)
|
||||
else:
|
||||
document_embedder = SentenceTransformersDocumentEmbedder(model=self.model_embeddings)
|
||||
document_writer = DocumentWriter(document_store=self.document_store)
|
||||
|
||||
indexing_pipeline = Pipeline()
|
||||
indexing_pipeline.add_component("document_splitter", document_splitter)
|
||||
indexing_pipeline.add_component("document_embedder", document_embedder)
|
||||
indexing_pipeline.add_component("document_writer", document_writer)
|
||||
|
||||
indexing_pipeline.connect("document_splitter", "document_embedder")
|
||||
indexing_pipeline.connect("document_embedder", "document_writer")
|
||||
|
||||
return indexing_pipeline
|
||||
|
||||
def _create_query_pipeline(self):
|
||||
print("Creating hybrid retrival pipeline ...")
|
||||
if config_backend.needs_torch:
|
||||
text_embedder = SentenceTransformersTextEmbedder(model=self.model_embeddings, device=self.gpu)
|
||||
ranker = TransformersSimilarityRanker(model=self.model_ranker, device=self.gpu)
|
||||
else:
|
||||
text_embedder = SentenceTransformersTextEmbedder(model=self.model_embeddings)
|
||||
ranker = TransformersSimilarityRanker(model=self.model_ranker)
|
||||
embedding_retriever = PgvectorEmbeddingRetriever(document_store=self.document_store)
|
||||
keyword_retriever = PgvectorKeywordRetriever(document_store=self.document_store)
|
||||
document_joiner = DocumentJoiner()
|
||||
|
||||
hybrid_retrieval = Pipeline()
|
||||
hybrid_retrieval.add_component("text_embedder", text_embedder)
|
||||
hybrid_retrieval.add_component("embedding_retriever", embedding_retriever)
|
||||
hybrid_retrieval.add_component("keyword_retriever", keyword_retriever)
|
||||
hybrid_retrieval.add_component("document_joiner", document_joiner)
|
||||
hybrid_retrieval.add_component("ranker", ranker)
|
||||
|
||||
hybrid_retrieval.connect("text_embedder", "embedding_retriever")
|
||||
hybrid_retrieval.connect("keyword_retriever", "document_joiner")
|
||||
hybrid_retrieval.connect("embedding_retriever", "document_joiner")
|
||||
hybrid_retrieval.connect("document_joiner", "ranker")
|
||||
|
||||
return hybrid_retrieval
|
||||
|
||||
def query(self, query: str):
|
||||
if not self._ready:
|
||||
raise SystemError("Cannot query when warmup hasn't been run yet")
|
||||
|
||||
return self.query_pipeline.run(
|
||||
data={
|
||||
"text_embedder": { "text": query },
|
||||
"keyword_retriever": { "query": query },
|
||||
"ranker": { "query": query, "top_k": 5 }
|
||||
}
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def format_result(result):
|
||||
result_table = []
|
||||
x: Document | None
|
||||
for x in result["ranker"]["documents"]:
|
||||
if x is None:
|
||||
continue
|
||||
result_table.append([f"[ {x.meta['id']:4} ]", x.meta["title"], x.meta["url"]])
|
||||
return result_table
|
||||
|
||||
@staticmethod
|
||||
def format_for_api(result):
|
||||
results = []
|
||||
x: Document | None
|
||||
for x in result["ranker"]["documents"]:
|
||||
if x is None:
|
||||
continue
|
||||
results.append({
|
||||
"id": x.meta["id"],
|
||||
"title": x.meta["title"],
|
||||
"url": x.meta["url"]
|
||||
})
|
||||
return results
|
||||
|
||||
|
||||
def load_data(dataset_path):
|
||||
data = []
|
||||
|
||||
with open(dataset_path, "r") as f:
|
||||
for x in f.readlines():
|
||||
j: dict = json.loads(x)
|
||||
j.update({
|
||||
"text": f"{j['title']} | {j['transcript']} | {j['explanation']}",
|
||||
"meta": { "title": j["title"], "url": j["url"], "image_url": j["image_url"], "id": j["id"] }
|
||||
}
|
||||
)
|
||||
data.append(j)
|
||||
return data
|
||||
|
||||
def get_torch_info():
|
||||
print("---------- Getting information about pytorch setup ----------")
|
||||
print(f"Is CUDA or ROCm available? { 'Yes' if torch.cuda.is_available() else 'No'}")
|
||||
print("Available devices:")
|
||||
for i in range(torch.cuda.device_count()):
|
||||
dev = torch.cuda.get_device_properties(i)
|
||||
print(f"- [{i}] {dev.name} [ {dev.multi_processor_count} processors, {dev.total_memory / 1_000_000_000:.2f} GB ]")
|
||||
print("-------------------------------------------------------------")
|
||||
2
server-implementation/config_backend.py
Normal file
2
server-implementation/config_backend.py
Normal file
|
|
@ -0,0 +1,2 @@
|
|||
needs_torch = True
|
||||
load_dataset = True
|
||||
101
server-implementation/templates/index.html
Normal file
101
server-implementation/templates/index.html
Normal file
|
|
@ -0,0 +1,101 @@
|
|||
<!DOCTYPE html>
|
||||
<head>
|
||||
<title>xkcd-finder</title>
|
||||
</head>
|
||||
<body>
|
||||
<div>
|
||||
<h1 class="head">xkcd-finder</h1>
|
||||
<h2 class="sub">Find me an xkcd for the topic ...</h2>
|
||||
<form action="/search" method="POST">
|
||||
{{form.csrf_token}}
|
||||
{{form.ids}}
|
||||
{{form.submit}}
|
||||
</form>
|
||||
</div>
|
||||
</body>
|
||||
|
||||
<style>
|
||||
* {
|
||||
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
|
||||
}
|
||||
|
||||
body {
|
||||
background: #1b1b1b;
|
||||
margin: 0px;
|
||||
width: auto;
|
||||
}
|
||||
|
||||
div {
|
||||
display: flex;
|
||||
flex-flow: column;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
padding-top: 12.5rem;
|
||||
}
|
||||
|
||||
form {
|
||||
display: flex;
|
||||
flex-flow: column;
|
||||
width: 45%;
|
||||
height: auto;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
form > input[type=text] {
|
||||
font-weight: 500;
|
||||
color: #eee;
|
||||
padding: 0.5rem 0.75rem;
|
||||
text-decoration: none;
|
||||
background-color: #333;
|
||||
border-radius: 10px;
|
||||
border-style: solid;
|
||||
border-width: 2px;
|
||||
border-color: #b86cff;
|
||||
height: 2rem;
|
||||
width: 100%;
|
||||
font-size: 2rem;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
form > input[type=submit] {
|
||||
font-weight: 500;
|
||||
font-size: 1.5rem;
|
||||
color: #eee;
|
||||
margin: 1rem 0px 0px;
|
||||
padding: 0.5rem 0.75rem;
|
||||
text-decoration: none;
|
||||
background-color: #333;
|
||||
border-radius: 10px;
|
||||
border-style: solid;
|
||||
border-width: 2px;
|
||||
border-color: #333;
|
||||
text-transform: capitalize;
|
||||
text-align: center;
|
||||
width: 50%;
|
||||
}
|
||||
|
||||
form > input[type=submit]:hover {
|
||||
border-color: #b86cff;
|
||||
}
|
||||
|
||||
.head {
|
||||
margin: 0 .5rem;
|
||||
hyphens: auto;
|
||||
padding-top: 2rem;
|
||||
font-size: 3.25rem;
|
||||
font-weight: 700;
|
||||
}
|
||||
|
||||
.sub {
|
||||
margin: 0 .5rem;
|
||||
font-size: 1.2rem;
|
||||
font-weight: 500;
|
||||
color: #eee;
|
||||
padding-bottom: 1rem;
|
||||
}
|
||||
|
||||
.head {
|
||||
color: #b86cff;
|
||||
}
|
||||
|
||||
</style>
|
||||
151
server-implementation/templates/results.html
Normal file
151
server-implementation/templates/results.html
Normal file
|
|
@ -0,0 +1,151 @@
|
|||
<!doctype html>
|
||||
<head>
|
||||
<meta charset="UTF-8" />
|
||||
<meta name="viewport" content="width=device-width" />
|
||||
<title>xkcd-finder - results for {{ topic }}</title>
|
||||
</head>
|
||||
<body>
|
||||
<section>
|
||||
<h1 class="head">Results</h1>
|
||||
<span class="sub">These are the top 5 results for the topic "{{ topic }}"</span>
|
||||
<ul>
|
||||
<li>
|
||||
<span class="title">{{ results[0]["title"] }}</span>
|
||||
<span class="id">xkdc {{ results[0]["id"] }}</span>
|
||||
<a target="_blank" rel="noopener noreferrer" class="xkcdlink" href={{ results[0]["url"] }}>Link >></a>
|
||||
</li>
|
||||
<li>
|
||||
<span class="title">{{ results[1]["title"] }}</span>
|
||||
<span class="id">xkdc {{ results[1]["id"] }}</span>
|
||||
<a target="_blank" rel="noopener noreferrer" class="xkcdlink" href={{ results[1]["url"] }}>Link >></a>
|
||||
</li>
|
||||
<li>
|
||||
<span class="title">{{ results[2]["title"] }}</span>
|
||||
<span class="id">xkdc {{ results[2]["id"] }}</span>
|
||||
<a target="_blank" rel="noopener noreferrer" class="xkcdlink" href={{ results[2]["url"] }}>Link >></a>
|
||||
</li>
|
||||
<li>
|
||||
<span class="title">{{ results[3]["title"] }}</span>
|
||||
<span class="id">xkdc {{ results[3]["id"] }}</span>
|
||||
<a target="_blank" rel="noopener noreferrer" class="xkcdlink" href={{ results[3]["url"] }}>Link >></a>
|
||||
</li>
|
||||
<li>
|
||||
<span class="title">{{ results[4]["title"] }}</span>
|
||||
<span class="id">xkdc {{ results[4]["id"] }}</span>
|
||||
<a target="_blank" rel="noopener noreferrer" class="xkcdlink" href={{ results[4]["url"] }}>Link >></a>
|
||||
</li>
|
||||
</ul>
|
||||
<a href="/" class="backbutton"><< Back to Home</a>
|
||||
</section>
|
||||
</body>
|
||||
|
||||
<style>
|
||||
* {
|
||||
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
|
||||
}
|
||||
|
||||
body {
|
||||
background: #1b1b1b;
|
||||
margin: 0px;
|
||||
width: auto;
|
||||
}
|
||||
|
||||
section {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
ul {
|
||||
display: flex;
|
||||
flex-direction: row;
|
||||
width: 100%;
|
||||
height: auto;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
text-decoration: none;
|
||||
list-style: none;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
li {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
position: relative;
|
||||
width: 220px;
|
||||
height: 250px;
|
||||
border: 2px solid #b86cff;
|
||||
margin: 1rem;
|
||||
justify-items: flex-start;
|
||||
align-items: center;
|
||||
border-radius: 10px;
|
||||
}
|
||||
|
||||
span {
|
||||
text-wrap: wrap;
|
||||
}
|
||||
|
||||
.title {
|
||||
padding-top: 10px;
|
||||
padding-left: 5px;
|
||||
padding-right: 5px;
|
||||
color: #eee;
|
||||
font-size: 2.1rem;
|
||||
font-weight: 600;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
.id {
|
||||
position: absolute;
|
||||
bottom: 56px;
|
||||
width: 70%;
|
||||
margin-left: auto;
|
||||
margin-right: auto;
|
||||
text-align: center;
|
||||
font-size: 1.2rem;
|
||||
color: #eee;
|
||||
}
|
||||
|
||||
.xkcdlink {
|
||||
position: absolute;
|
||||
bottom: 10px;
|
||||
width: 70%;
|
||||
}
|
||||
|
||||
a {
|
||||
font-weight: 500;
|
||||
color: #eee;
|
||||
padding: 0.5rem 0.75rem;
|
||||
text-decoration: none;
|
||||
background-color: #333;
|
||||
border-radius: 10px;
|
||||
border-style: solid;
|
||||
border-width: 2px;
|
||||
border-color: #333;
|
||||
text-transform: capitalize;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
a:hover {
|
||||
border-color: #b86cff;
|
||||
}
|
||||
|
||||
.head {
|
||||
margin: 0 .5rem;
|
||||
hyphens: auto;
|
||||
padding-top: 5rem;
|
||||
font-size: 3.25rem;
|
||||
font-weight: 700;
|
||||
}
|
||||
|
||||
.sub {
|
||||
margin: 0 .5rem;
|
||||
font-size: 1.2rem;
|
||||
font-weight: 500;
|
||||
color: #eee;
|
||||
}
|
||||
|
||||
.head {
|
||||
color: #b86cff;
|
||||
}
|
||||
</style>
|
||||
Loading…
Add table
Add a link
Reference in a new issue