Initial commit
This commit is contained in:
commit
b135ce28c5
5 changed files with 439 additions and 0 deletions
1
.gitattributes
vendored
Normal file
1
.gitattributes
vendored
Normal file
|
|
@ -0,0 +1 @@
|
|||
data/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
7
.gitignore
vendored
Normal file
7
.gitignore
vendored
Normal file
|
|
@ -0,0 +1,7 @@
|
|||
# env
|
||||
.env
|
||||
*venv/
|
||||
|
||||
# Binaries for installation
|
||||
*.deb
|
||||
*.whl
|
||||
BIN
data/dataset.jsonl
(Stored with Git LFS)
Normal file
BIN
data/dataset.jsonl
(Stored with Git LFS)
Normal file
Binary file not shown.
BIN
hybrid-retrieval.png
Normal file
BIN
hybrid-retrieval.png
Normal file
{kind=link}
Binary file not shown.
|
After 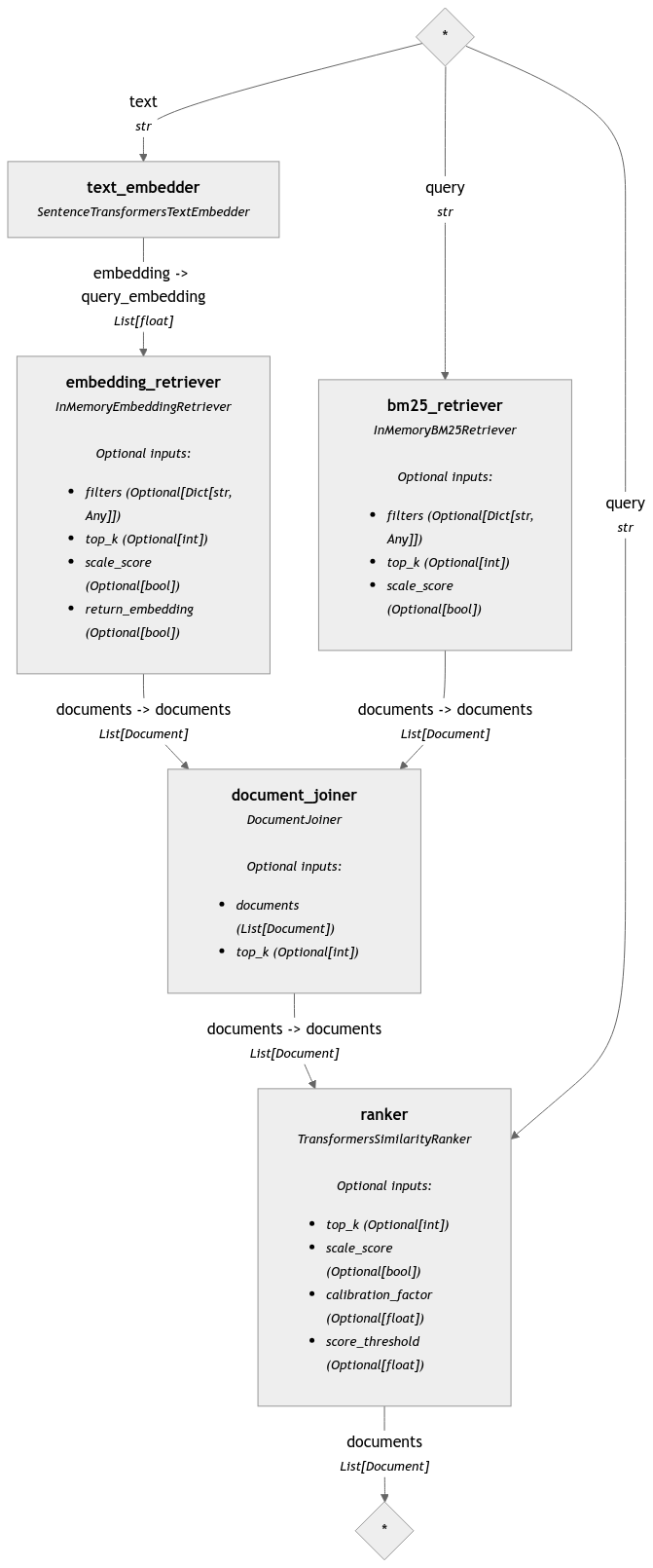
(image error) Size: 128 KiB |
428
nlp.ipynb
Normal file
428
nlp.ipynb
Normal file
|
|
@ -0,0 +1,428 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"metadata": {}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Is CUDA or ROCm available? Yes\n",
|
||||
"Available devices:\n",
|
||||
"- [0] AMD Radeon RX 7900 XT [ 42 processors, 21.39 GB ]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"print(f\"Is CUDA or ROCm available? { 'Yes' if torch.cuda.is_available() else 'No'}\")\n",
|
||||
"print(\"Available devices:\")\n",
|
||||
"for i in range(torch.cuda.device_count()):\n",
|
||||
" dev = torch.cuda.get_device_properties(i)\n",
|
||||
" print(f\"- [{i}] {dev.name} [ {dev.multi_processor_count} processors, {dev.total_memory / 1_000_000_000:.2f} GB ]\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from haystack.utils import ComponentDevice\n",
|
||||
"gpu = ComponentDevice.from_str(\"cuda:0\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"metadata": {}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>id</th>\n",
|
||||
" <th>title</th>\n",
|
||||
" <th>image_title</th>\n",
|
||||
" <th>url</th>\n",
|
||||
" <th>image_url</th>\n",
|
||||
" <th>explained_url</th>\n",
|
||||
" <th>transcript</th>\n",
|
||||
" <th>explanation</th>\n",
|
||||
" <th>text</th>\n",
|
||||
" <th>meta</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>0</th>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>Barrel - Part 1</td>\n",
|
||||
" <td>Barrel - Part 1</td>\n",
|
||||
" <td>https://www.xkcd.com/1</td>\n",
|
||||
" <td>https://imgs.xkcd.com/comics/barrel_cropped_(1...</td>\n",
|
||||
" <td>https://www.explainxkcd.com/wiki/index.php/1:_...</td>\n",
|
||||
" <td>[A boy sits in a barrel which is floating in a...</td>\n",
|
||||
" <td>This was the fifth comic originally posted to ...</td>\n",
|
||||
" <td>barrel - part 1 | [a boy sits in a barrel whic...</td>\n",
|
||||
" <td>{'title': 'Barrel - Part 1', 'url': 'https://w...</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>1</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>Petit Trees (sketch)</td>\n",
|
||||
" <td>Petit Trees (sketch)</td>\n",
|
||||
" <td>https://www.xkcd.com/2</td>\n",
|
||||
" <td>https://imgs.xkcd.com/comics/tree_cropped_(1).jpg</td>\n",
|
||||
" <td>https://www.explainxkcd.com/wiki/index.php/2:_...</td>\n",
|
||||
" <td>[Two trees are growing on opposite sides of a ...</td>\n",
|
||||
" <td>This was the fourth comic originally posted to...</td>\n",
|
||||
" <td>petit trees (sketch) | [two trees are growing ...</td>\n",
|
||||
" <td>{'title': 'Petit Trees (sketch)', 'url': 'http...</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2</th>\n",
|
||||
" <td>3</td>\n",
|
||||
" <td>Island (sketch)</td>\n",
|
||||
" <td>Island (sketch)</td>\n",
|
||||
" <td>https://www.xkcd.com/3</td>\n",
|
||||
" <td>https://imgs.xkcd.com/comics/island_color.jpg</td>\n",
|
||||
" <td>https://www.explainxkcd.com/wiki/index.php/3:_...</td>\n",
|
||||
" <td>[A green island surrounded by blue water]\\nThi...</td>\n",
|
||||
" <td>This was the third comic originally posted to ...</td>\n",
|
||||
" <td>island (sketch) | [a green island surrounded b...</td>\n",
|
||||
" <td>{'title': 'Island (sketch)', 'url': 'https://w...</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3</th>\n",
|
||||
" <td>4</td>\n",
|
||||
" <td>Landscape (sketch)</td>\n",
|
||||
" <td>Landscape (sketch)</td>\n",
|
||||
" <td>https://www.xkcd.com/4</td>\n",
|
||||
" <td>https://imgs.xkcd.com/comics/landscape_cropped...</td>\n",
|
||||
" <td>https://www.explainxkcd.com/wiki/index.php/4:_...</td>\n",
|
||||
" <td>[A sketch of a landscape with sun on the horiz...</td>\n",
|
||||
" <td>This was the second comic originally posted to...</td>\n",
|
||||
" <td>landscape (sketch) | [a sketch of a landscape ...</td>\n",
|
||||
" <td>{'title': 'Landscape (sketch)', 'url': 'https:...</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>4</th>\n",
|
||||
" <td>5</td>\n",
|
||||
" <td>Blown apart</td>\n",
|
||||
" <td>Blown apart</td>\n",
|
||||
" <td>https://www.xkcd.com/5</td>\n",
|
||||
" <td>https://imgs.xkcd.com/comics/blownapart_color.jpg</td>\n",
|
||||
" <td>https://www.explainxkcd.com/wiki/index.php/5:_...</td>\n",
|
||||
" <td>[A black number 70 sees a red package with the...</td>\n",
|
||||
" <td>This comic is a mathematical and technical jok...</td>\n",
|
||||
" <td>blown apart | [a black number 70 sees a red pa...</td>\n",
|
||||
" <td>{'title': 'Blown apart', 'url': 'https://www.x...</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" id title image_title url \\\n",
|
||||
"0 1 Barrel - Part 1 Barrel - Part 1 https://www.xkcd.com/1 \n",
|
||||
"1 2 Petit Trees (sketch) Petit Trees (sketch) https://www.xkcd.com/2 \n",
|
||||
"2 3 Island (sketch) Island (sketch) https://www.xkcd.com/3 \n",
|
||||
"3 4 Landscape (sketch) Landscape (sketch) https://www.xkcd.com/4 \n",
|
||||
"4 5 Blown apart Blown apart https://www.xkcd.com/5 \n",
|
||||
"\n",
|
||||
" image_url \\\n",
|
||||
"0 https://imgs.xkcd.com/comics/barrel_cropped_(1... \n",
|
||||
"1 https://imgs.xkcd.com/comics/tree_cropped_(1).jpg \n",
|
||||
"2 https://imgs.xkcd.com/comics/island_color.jpg \n",
|
||||
"3 https://imgs.xkcd.com/comics/landscape_cropped... \n",
|
||||
"4 https://imgs.xkcd.com/comics/blownapart_color.jpg \n",
|
||||
"\n",
|
||||
" explained_url \\\n",
|
||||
"0 https://www.explainxkcd.com/wiki/index.php/1:_... \n",
|
||||
"1 https://www.explainxkcd.com/wiki/index.php/2:_... \n",
|
||||
"2 https://www.explainxkcd.com/wiki/index.php/3:_... \n",
|
||||
"3 https://www.explainxkcd.com/wiki/index.php/4:_... \n",
|
||||
"4 https://www.explainxkcd.com/wiki/index.php/5:_... \n",
|
||||
"\n",
|
||||
" transcript \\\n",
|
||||
"0 [A boy sits in a barrel which is floating in a... \n",
|
||||
"1 [Two trees are growing on opposite sides of a ... \n",
|
||||
"2 [A green island surrounded by blue water]\\nThi... \n",
|
||||
"3 [A sketch of a landscape with sun on the horiz... \n",
|
||||
"4 [A black number 70 sees a red package with the... \n",
|
||||
"\n",
|
||||
" explanation \\\n",
|
||||
"0 This was the fifth comic originally posted to ... \n",
|
||||
"1 This was the fourth comic originally posted to... \n",
|
||||
"2 This was the third comic originally posted to ... \n",
|
||||
"3 This was the second comic originally posted to... \n",
|
||||
"4 This comic is a mathematical and technical jok... \n",
|
||||
"\n",
|
||||
" text \\\n",
|
||||
"0 barrel - part 1 | [a boy sits in a barrel whic... \n",
|
||||
"1 petit trees (sketch) | [two trees are growing ... \n",
|
||||
"2 island (sketch) | [a green island surrounded b... \n",
|
||||
"3 landscape (sketch) | [a sketch of a landscape ... \n",
|
||||
"4 blown apart | [a black number 70 sees a red pa... \n",
|
||||
"\n",
|
||||
" meta \n",
|
||||
"0 {'title': 'Barrel - Part 1', 'url': 'https://w... \n",
|
||||
"1 {'title': 'Petit Trees (sketch)', 'url': 'http... \n",
|
||||
"2 {'title': 'Island (sketch)', 'url': 'https://w... \n",
|
||||
"3 {'title': 'Landscape (sketch)', 'url': 'https:... \n",
|
||||
"4 {'title': 'Blown apart', 'url': 'https://www.x... "
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import json\n",
|
||||
"import pathlib\n",
|
||||
"\n",
|
||||
"import pandas as pd\n",
|
||||
"\n",
|
||||
"dataset = pathlib.Path(\"data\") / \"dataset.jsonl\"\n",
|
||||
"data = []\n",
|
||||
"\n",
|
||||
"with open(dataset, \"r\") as f:\n",
|
||||
" for x in f.readlines():\n",
|
||||
" j = json.loads(x)\n",
|
||||
" j.update({ \"text\": f\"{j['title']} | {j['transcript']} | {j['explanation']}\".lower() })\n",
|
||||
" j.update({ \"meta\": {\n",
|
||||
" \"title\": j[\"title\"],\n",
|
||||
" \"url\": j[\"url\"],\n",
|
||||
" \"image_url\": j[\"image_url\"],\n",
|
||||
" \"id\": j[\"id\"]\n",
|
||||
" }})\n",
|
||||
" data.append(j)\n",
|
||||
"\n",
|
||||
"df = pd.DataFrame(data)\n",
|
||||
"\n",
|
||||
"df.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"metadata": {}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "6e3b2d47cde54d50a8a92305bda7fed4",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
"Batches: 0%| | 0/167 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Finished running pipeline\n",
|
||||
"Result: Wrote 5343 to document store\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from haystack import Document, Pipeline\n",
|
||||
"from haystack.components.embedders import SentenceTransformersDocumentEmbedder\n",
|
||||
"from haystack.components.preprocessors.document_splitter import DocumentSplitter\n",
|
||||
"from haystack.components.writers import DocumentWriter\n",
|
||||
"from haystack.document_stores.in_memory import InMemoryDocumentStore\n",
|
||||
"\n",
|
||||
"model_embeddings = \"BAAI/bge-small-en-v1.5\"\n",
|
||||
"model_ranker = \"BAAI/bge-reranker-base\"\n",
|
||||
"\n",
|
||||
"results = [Document(content=d[\"text\"], meta=d[\"meta\"]) for d in data]\n",
|
||||
"document_store = InMemoryDocumentStore()\n",
|
||||
"\n",
|
||||
"document_splitter = DocumentSplitter(split_by=\"word\", split_length=512, split_overlap=32)\n",
|
||||
"document_embedder = SentenceTransformersDocumentEmbedder(model=model_embeddings, device=gpu)\n",
|
||||
"document_writer = DocumentWriter(document_store)\n",
|
||||
"\n",
|
||||
"indexing_pipeline = Pipeline()\n",
|
||||
"indexing_pipeline.add_component(\"document_splitter\", document_splitter)\n",
|
||||
"indexing_pipeline.add_component(\"document_embedder\", document_embedder)\n",
|
||||
"indexing_pipeline.add_component(\"document_writer\", document_writer)\n",
|
||||
"\n",
|
||||
"indexing_pipeline.connect(\"document_splitter\", \"document_embedder\")\n",
|
||||
"indexing_pipeline.connect(\"document_embedder\", \"document_writer\")\n",
|
||||
"\n",
|
||||
"res = indexing_pipeline.run({\"document_splitter\": {\"documents\": results}})\n",
|
||||
"\n",
|
||||
"print(f\"Finished running indexing pipeline\\nResult: Wrote {res['document_writer']['documents_written']} to document store\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"<haystack.core.pipeline.pipeline.Pipeline object at 0x7f7315fc1b10>\n",
|
||||
"🚅 Components\n",
|
||||
" - text_embedder: SentenceTransformersTextEmbedder\n",
|
||||
" - embedding_retriever: InMemoryEmbeddingRetriever\n",
|
||||
" - bm25_retriever: InMemoryBM25Retriever\n",
|
||||
" - document_joiner: DocumentJoiner\n",
|
||||
" - ranker: TransformersSimilarityRanker\n",
|
||||
"🛤️ Connections\n",
|
||||
" - text_embedder.embedding -> embedding_retriever.query_embedding (List[float])\n",
|
||||
" - embedding_retriever.documents -> document_joiner.documents (List[Document])\n",
|
||||
" - bm25_retriever.documents -> document_joiner.documents (List[Document])\n",
|
||||
" - document_joiner.documents -> ranker.documents (List[Document])"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from haystack.components.embedders import SentenceTransformersTextEmbedder\n",
|
||||
"from haystack.components.joiners import DocumentJoiner\n",
|
||||
"from haystack.components.rankers import TransformersSimilarityRanker\n",
|
||||
"from haystack.components.retrievers.in_memory import InMemoryBM25Retriever, InMemoryEmbeddingRetriever\n",
|
||||
"\n",
|
||||
"text_embedder = SentenceTransformersTextEmbedder(model=model_embeddings, device=gpu, progress_bar=False)\n",
|
||||
"embedding_retriever = InMemoryEmbeddingRetriever(document_store)\n",
|
||||
"bm25_retriever = InMemoryBM25Retriever(document_store)\n",
|
||||
"document_joiner = DocumentJoiner()\n",
|
||||
"ranker = TransformersSimilarityRanker(model=model_ranker, device=gpu)\n",
|
||||
"\n",
|
||||
"hybrid_retrieval = Pipeline()\n",
|
||||
"hybrid_retrieval.add_component(\"text_embedder\", text_embedder)\n",
|
||||
"hybrid_retrieval.add_component(\"embedding_retriever\", embedding_retriever)\n",
|
||||
"hybrid_retrieval.add_component(\"bm25_retriever\", bm25_retriever)\n",
|
||||
"hybrid_retrieval.add_component(\"document_joiner\", document_joiner)\n",
|
||||
"hybrid_retrieval.add_component(\"ranker\", ranker)\n",
|
||||
"\n",
|
||||
"hybrid_retrieval.connect(\"text_embedder\", \"embedding_retriever\")\n",
|
||||
"hybrid_retrieval.connect(\"bm25_retriever\", \"document_joiner\")\n",
|
||||
"hybrid_retrieval.connect(\"embedding_retriever\", \"document_joiner\")\n",
|
||||
"hybrid_retrieval.connect(\"document_joiner\", \"ranker\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"hybrid_retrieval.draw(\"hybrid-retrieval.png\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Results for 'Give an example for dependency'\n",
|
||||
"\n",
|
||||
"| ID | Title | Link |\n",
|
||||
"|----------|------------------|---------------------------|\n",
|
||||
"| [ 1579 ] | Tech Loops | https://www.xkcd.com/1579 |\n",
|
||||
"| [ 1906 ] | Making Progress | https://www.xkcd.com/1906 |\n",
|
||||
"| [ 2102 ] | Internet Archive | https://www.xkcd.com/2102 |\n",
|
||||
"| [ 2347 ] | Dependency | https://www.xkcd.com/2347 |\n",
|
||||
"| [ 1988 ] | Containers | https://www.xkcd.com/1988 |\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from tabulate import tabulate\n",
|
||||
"\n",
|
||||
"query = \"Give an example for dependency\"\n",
|
||||
"\n",
|
||||
"result = hybrid_retrieval.run(\n",
|
||||
" data={\n",
|
||||
" \"text_embedder\": {\n",
|
||||
" \"text\": query\n",
|
||||
" },\n",
|
||||
" \"bm25_retriever\": {\n",
|
||||
" \"query\": query\n",
|
||||
" },\n",
|
||||
" \"ranker\": {\n",
|
||||
" \"query\": query,\n",
|
||||
" \"top_k\": 5\n",
|
||||
" }\n",
|
||||
" }\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"result_table = []\n",
|
||||
"headers = [\"ID\", \"Title\", \"Link\"]\n",
|
||||
"\n",
|
||||
"x: Document | None\n",
|
||||
"for x in result[\"ranker\"][\"documents\"]:\n",
|
||||
" if x is None:\n",
|
||||
" continue\n",
|
||||
" result_table.append([f\"[ {x.id:4} ]\", x.meta[\"title\"], x.meta[\"url\"]])\n",
|
||||
"\n",
|
||||
"print(f\"Results for '{query}'\\n\")\n",
|
||||
"print(tabulate(result_table, headers=headers, tablefmt=\"github\"))"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
Loading…
Add table
Add a link
Reference in a new issue